Improving Answer Quality with Markdown Indexing
To deliver more accurate, context-rich answers at scale, Ask AI benefits from cleanly structured content. One of the most effective ways to achieve this is by using a Markdown-based indexing helper in your Algolia Crawler configuration. This setup ensures Ask AI can access well-formed, content-focused records—especially important for larger documentation sites where metadata, navigation elements, or layout artifacts might otherwise dilute the quality of generative responses.
Setting up markdown indexing can be automated through the Crawler UI for most use cases. For advanced customization or understanding the underlying configuration, manual setup options are also available.
Note: For more integration examples (Docusaurus, VitePress, Astro/Starlight, and generic setups), see the section at the bottom of this page.
Overview
To maximize the quality of Ask AI responses, configure your Crawler to create a dedicated index for Markdown content. This approach enables Ask AI to work with structured, chunked records sourced from your documentation, support content, or any Markdown-based material—resulting in significantly more relevant and precise answers.
You can set up markdown indexing in two ways:
- Automated Setup (Recommended): Use the Crawler UI to automatically create and configure your markdown index
- Manual Configuration: Manually configure your Crawler for advanced customization needs
Automated Markdown Indexing Setup (Recommended)
The easiest way to set up markdown indexing is through the Crawler UI, which automatically creates and configures an optimized markdown index for Ask AI.
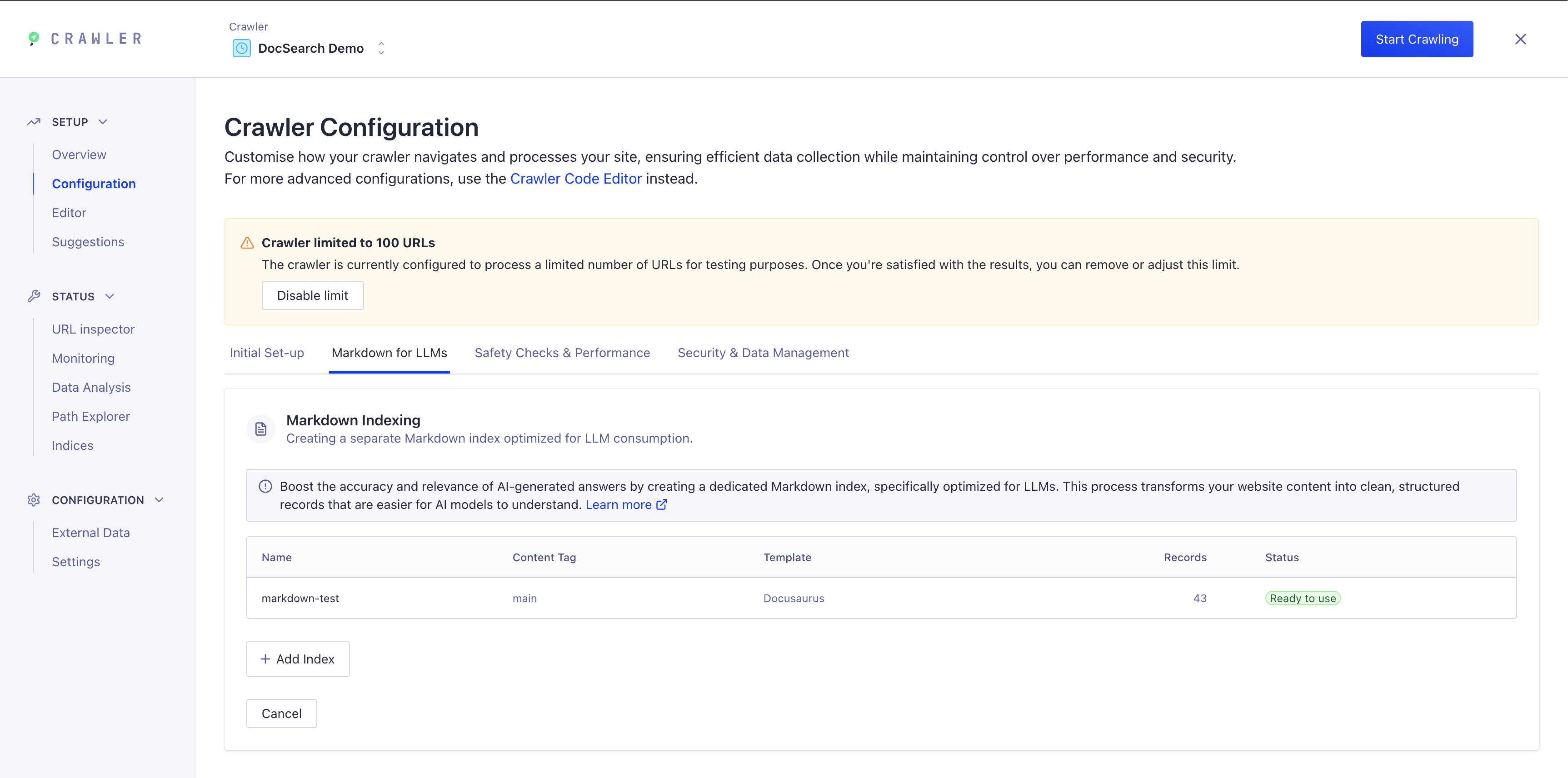
Step 1: Access Markdown Indexing in Crawler Configuration
- Navigate to your Crawler dashboard
- Go to Configuration → Markdown for LLMs tab
- You'll see the Markdown Indexing section where you can create a dedicated markdown index
Step 2: Add a New Markdown Index
- Click "+ Add Index" to create a new markdown index
- Fill in the required fields:
- Index Name: Enter a descriptive name (e.g.,
my-docs-markdown) - Content Tag: Specify the HTML content selector (typically
main) - Template: Choose the template that matches your documentation framework:
- Docusaurus - For Docusaurus sites
- VitePress - For VitePress sites
- Astro/Starlight - For Astro/Starlight sites
- Non-DocSearch (Generic) - For custom sites or other frameworks
- Index Name: Enter a descriptive name (e.g.,
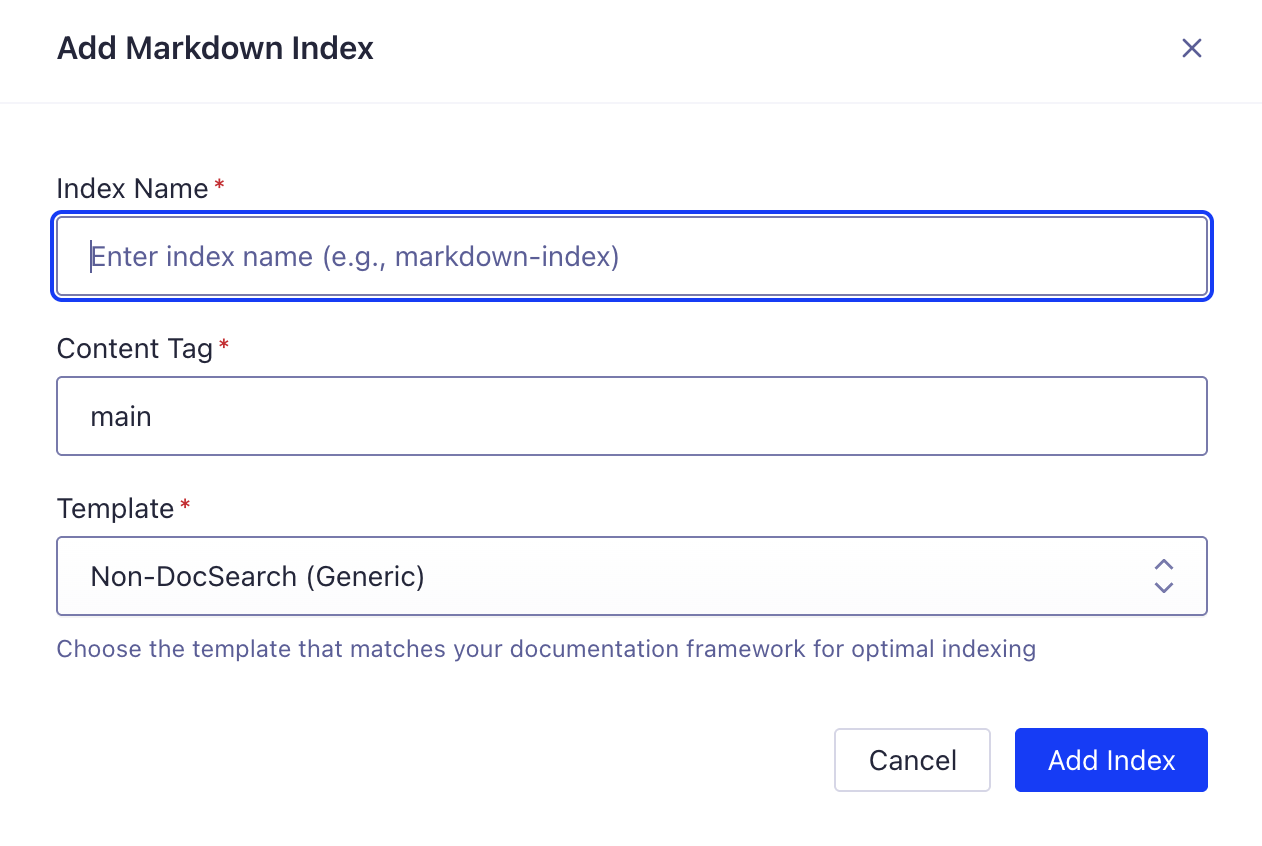
- Click "Add Index" to create the index
The Crawler will automatically configure the optimal settings for your chosen template, including:
- Proper record extraction and chunking
- Framework-specific metadata extraction (language, version, tags)
- Optimized index settings for Ask AI
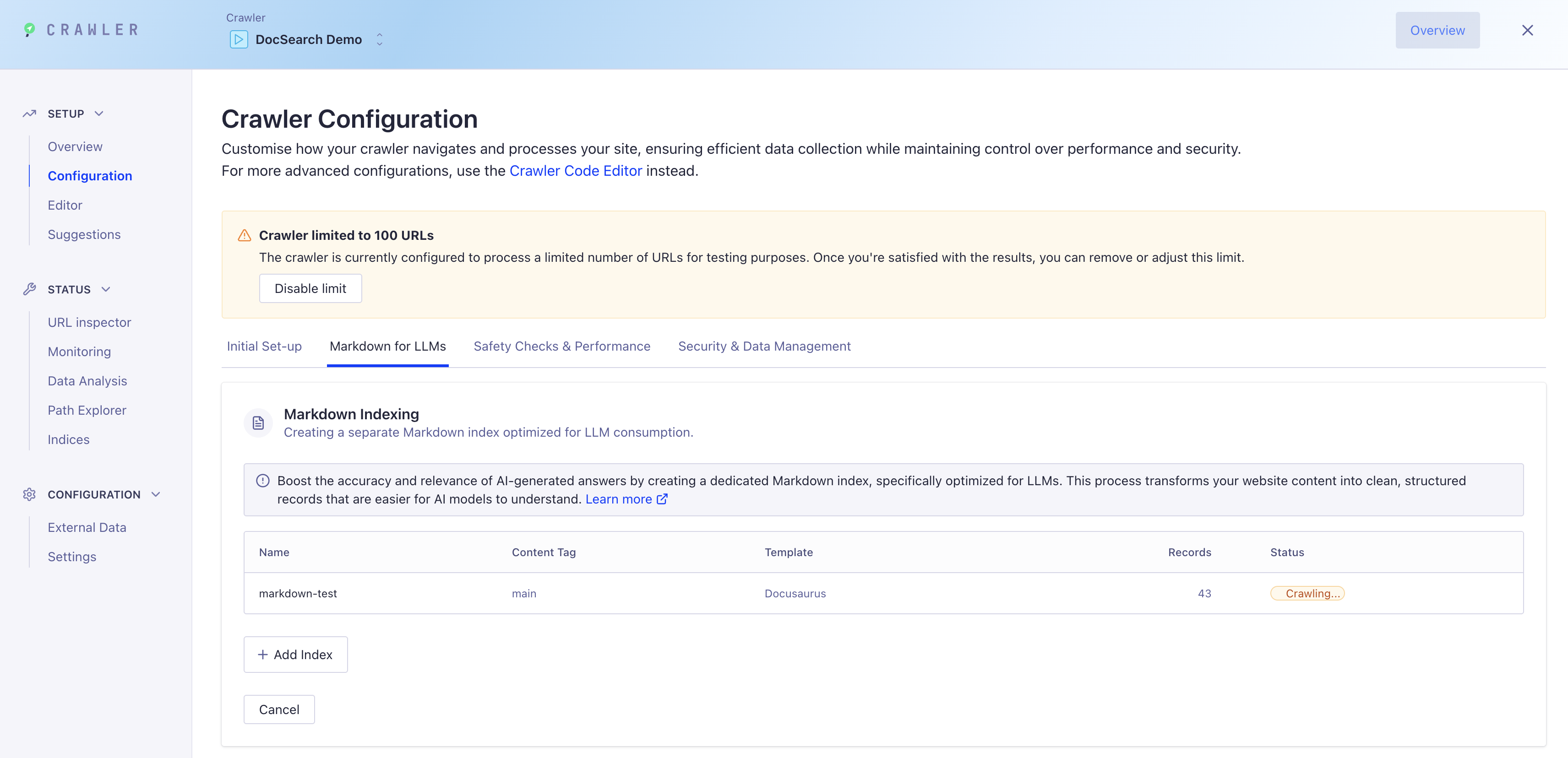
Step 3: Run the Crawler
Once your markdown index is configured:
- Click "Start Crawling" to begin indexing your content
- Monitor the crawl progress in the dashboard
- Your new markdown index will be populated with clean, structured records optimized for Ask AI
Step 4: Integrate with Ask AI
After crawling completes, configure DocSearch to use your new markdown index for Ask AI responses. See the Integration section below for detailed setup instructions.
Manual Configuration (Advanced)
For users who need advanced customization or want to understand the underlying configuration, you can manually set up markdown indexing by modifying your Crawler configuration directly.
Step 1: Update your existing DocSearch Crawler configuration
- In your Crawler config, add the following to your
actions: [ ... ]array:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language,
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
- Then, add the following to your
initialIndexSettings: { ... }object:
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"],
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
Step 2: Run the DocSearch crawler to create a new Ask AI optimized index
After updating your Crawler configuration:
- Publish your configuration in the Algolia Crawler dashboard to save and activate it.
- Run the Crawler to index your markdown content and create the new index.
The Crawler will process your content using the markdown extraction helper and populate your new index with clean, structured records optimized for Ask AI.
Tip: Monitor the crawl progress in your dashboard to ensure all pages are processed correctly. You can view the indexed records in your Algolia index to verify the structure and content.
Integrate your new index with Ask AI
Once your Crawler has created your optimized index, you can integrate it with Ask AI in two ways: using DocSearch (recommended for most users) or building a custom integration using the Ask AI API.
- DocSearch Integration
- Custom API Integration
Using DocSearch
Configure DocSearch to use both your main keyword index and your markdown index for Ask AI:
- JavaScript
- React
docsearch({
indexName: 'YOUR_INDEX_NAME', // Main DocSearch keyword index
apiKey: 'YOUR_SEARCH_API_KEY',
appId: 'YOUR_APP_ID',
askAi: {
indexName: 'YOUR_INDEX_NAME-markdown', // Markdown index for Ask AI
apiKey: 'YOUR_SEARCH_API_KEY', // (or a different key if needed)
appId: 'YOUR_APP_ID',
assistantId: 'YOUR_ALGOLIA_ASSISTANT_ID',
searchParameters: {
facetFilters: ['language:en'], // Optional: filter to specific language/version
},
},
});
<DocSearch
indexName="YOUR_INDEX_NAME" // Main DocSearch keyword index
apiKey="YOUR_SEARCH_API_KEY"
appId="YOUR_APP_ID"
askAi={{
indexName: 'YOUR_INDEX_NAME-markdown', // Markdown index for Ask AI
apiKey: 'YOUR_SEARCH_API_KEY',
appId: 'YOUR_APP_ID',
assistantId: 'YOUR_ALGOLIA_ASSISTANT_ID',
searchParameters: {
facetFilters: ['language:en'], // Optional: filter to specific language/version
},
}}
/>
indexName: Your main DocSearch index for keyword search.askAi.indexName: The markdown index you created for Ask AI context.assistantId: The ID of your configured Ask AI assistant.searchParameters.facetFilters: Optional filters to limit Ask AI context (useful for multi-language sites).
Custom API Integration
We highly recommend using the DocSearch package for most use cases. Custom implementations using the Ask AI API directly are not fully supported to the same extent as the DocSearch package, and may require additional development effort for features like error handling, authentication, and UI components.
Build your own chat interface using the Ask AI API. This gives you full control over the user experience and allows for advanced customizations.
class CustomAskAI {
constructor({ appId, apiKey, indexName, assistantId }) {
this.appId = appId;
this.apiKey = apiKey;
this.indexName = indexName; // Your markdown index
this.assistantId = assistantId;
this.baseUrl = 'https://askai.algolia.com';
}
async getToken() {
const response = await fetch(`${this.baseUrl}/chat/token`, {
method: 'POST',
headers: {
'X-Algolia-Assistant-Id': this.assistantId,
},
});
const data = await response.json();
return data.token;
}
async sendMessage(conversationId, messages, searchParameters = {}) {
const token = await this.getToken();
const response = await fetch(`${this.baseUrl}/chat`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Algolia-Application-Id': this.appId,
'X-Algolia-API-Key': this.apiKey,
'X-Algolia-Index-Name': this.indexName, // Use your markdown index
'X-Algolia-Assistant-Id': this.assistantId,
'Authorization': token,
},
body: JSON.stringify({
id: conversationId,
messages,
...(Object.keys(searchParameters).length > 0 && { searchParameters }),
}),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
// Handle streaming response
const reader = response.body.getReader();
const decoder = new TextDecoder();
return {
async *[Symbol.asyncIterator]() {
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value, { stream: true });
if (chunk.trim()) {
yield chunk;
}
}
} finally {
reader.releaseLock();
}
}
};
}
}
// Usage
const askAI = new CustomAskAI({
appId: 'YOUR_APP_ID',
apiKey: 'YOUR_API_KEY',
indexName: 'YOUR_INDEX_NAME-markdown', // Your markdown index
assistantId: 'YOUR_ASSISTANT_ID',
});
// Send a message with facet filters for your markdown index
const stream = await askAI.sendMessage('conversation-1', [
{
role: 'user',
content: 'How do I configure my API?',
id: 'msg-1',
},
], {
facetFilters: ['language:en', 'type:content'] // Filter to relevant content
});
// Handle streaming response
for await (const chunk of stream) {
console.log(chunk); // Handle each chunk of the response
}
Benefits of custom integration:
- Full control over UI/UX
- Custom authentication and session management
- Advanced filtering and search parameters for your markdown index
- Integration with existing chat systems
- Custom analytics and monitoring
📚 Learn More: For complete API documentation, authentication details, advanced examples, and more integration patterns, see the Ask AI API Reference.
Using Facet Filters with Your Markdown Index:
Since your markdown index includes attributes like lang, version, and docusaurus_tag, you can filter Ask AI's context precisely:
// Example: Filter to English documentation only
const searchParameters = {
facetFilters: ['lang:en']
};
// Example: Filter to specific version and content type
const searchParameters = {
facetFilters: ['lang:en', 'version:latest', 'type:content']
};
// Example: Use OR logic for multiple tags (from your integration examples)
const searchParameters = {
facetFilters: [
'lang:en',
[
'docusaurus_tag:default',
'docusaurus_tag:docs-default-current'
]
]
};
Tip: Keep both indexes updated as your documentation evolves to ensure the best search and AI answer quality.
Best Practices & Tips
- Use clear, consistent titles in your markdown files for better searchability.
- Test your index with Ask AI to ensure relevant answers are returned.
- Adjust
maxRecordBytesif you notice answers are too broad or too fragmented.- Note: Increasing
maxRecordBytesmay increase the token count for LLMs, which can affect the size of the context window and the cost of each Ask AI response.
- Note: Increasing
- Keep your markdown well-structured (use headings, lists, etc.) for optimal chunking.
- Add attributes like
lang,version, ortagsto your records andattributesForFacetingif you want to filter or facet in your search UI or Ask AI.
FAQ
Q: Why use a separate markdown index? A: It allows Ask AI to access content in a format optimized for LLMs, improving answer quality.
Q: Can I use this with other content types? A: Yes, but markdown is especially well-suited for chunking and context extraction.
Q: What if I have very large markdown files?
A: Lower the maxRecordBytes value to split content into smaller, more focused records.
For more details, see the Ask AI documentation or contact support if you need help configuring your Crawler.
Crawler Configuration Examples by Integration
Below are example configurations for setting up your markdown index with different documentation platforms. Each shows how to extract facets (like language, version, tags) and configure the Crawler for your specific integration:
- Non-DocSearch (Generic)
- Docusaurus
- VitePress
- Astro / Starlight
Generic Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language,
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"], // Recommended if you add more attributes outside of objectID
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
Docusaurus Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
// Extract meta tag values. These are required for Docusaurus
const language =
$('meta[name="docsearch:language"]').attr("content") || "en";
const version =
$('meta[name="docsearch:version"]').attr("content") || "latest";
const docusaurus_tag =
$('meta[name="docsearch:docusaurus_tag"]').attr("content") || "";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language, // Required for Docusaurus
language, // Required for Docusaurus
version: version.split(","), // in case there are multiple versions. Required for Docusaurus
docusaurus_tag: docusaurus_tag // Required for Docusaurus
.split(",")
.map((tag) => tag.trim())
.filter(Boolean),
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang", "language", "version", "docusaurus_tag"], // Required for Docusaurus
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
VitePress Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language, // Required for VitePress
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"], // Required for VitePress
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
Astro / Starlight Example:
// In your Crawler config:
// actions: [ ...,
{
indexName: "my-markdown-index",
pathsToMatch: ["https://example.com/docs/**"],
recordExtractor: ({ $, url, helpers }) => {
// Target only the main content, excluding navigation
const text = helpers.markdown(
"main > *:not(nav):not(header):not(.breadcrumb)",
);
if (text === "") return [];
const language = $("html").attr("lang") || "en";
const title = $("head > title").text();
// Get the main heading for better searchability
const h1 = $("main h1").first().text();
return helpers.splitTextIntoRecords({
text,
baseRecord: {
url,
objectID: url,
title: title || h1,
heading: h1, // Add main heading as separate field
lang: language, // Required for Astro/StarLight
},
maxRecordBytes: 100000, // Higher = fewer, larger records. Lower = more, smaller records.
// Note: Increasing this value may increase the token count for LLMs, which can affect context size and cost.
orderingAttributeName: "part",
});
},
},
// ...],
// initialIndexSettings: { ...,
"my-markdown-index": {
attributesForFaceting: ["lang"], // Required for Astro/StarLight
ignorePlurals: true,
minProximity: 1,
removeStopWords: false,
searchableAttributes: ["title", "heading", "unordered(text)"],
removeWordsIfNoResults: "lastWords",
attributesToHighlight: ["title", "text"],
typoTolerance: false,
advancedSyntax: false,
},
// ...},
Each example shows how to extract common facets and configure your markdown index for Ask AI. Adjust selectors and meta tag names as needed for your site.