Run your own
If you want to update your results with more control, or if you are not compliant with our checklist, or if your website sits behind a firewall, you might want to run the crawler yourself.
The whole code base of DocSearch is open source, and we package it as a Docker image to make this even easier for you to use.
Set up your environment
You'll need to set your Algolia application ID and admin API key as environment variables. If you don't have an Algolia account, you need to create one.
-
APPLICATION_IDset to your Algolia Application ID -
API_KEYset to your API Key. Make sure to use an API key with write access to your index. It needs the ACLaddObject,editSettingsanddeleteIndex.
For convenience, you can create a .env file in the repository root.
APPLICATION_ID=YOUR_APP_ID
API_KEY=YOUR_API_KEY
Run the crawl from the Docker image
You can run a crawl from the packaged Docker image to crawl your website. You will need to install jq, a lightweight command-line JSON processor
Then you need to start the crawl according to your configuration. You should check the dedicated configuration documentation.
docker run -it --env-file=.env -e "CONFIG=$(cat /path/to/your/config.json | jq -r tostring)" algolia/docsearch-scraper
Once the scraping finishes, you can jump to the Integration step.
Running the crawler from the code base
Installation
The scraper is a python tool based on scrapy. We do recommend to use pipenv to install the python environment.
- Clone the scraper repository.
- Install pipenv
pipenv installpipenv shell
If you plan to use the browser emulation (js_render set to true), you need to follow this extra step. If you don't, you can dismiss this step.
Installing Chrome driver
Some websites rendering requires JavaScript. Our crawler relies on a headless chrome emulation. You will need to set up a ChromeDriver.
- Install the driver suited to your OS and the version of your Chrome. We do recommend to use the latest version.
- Set the environment variable
CHROMEDRIVER_PATHin your.envfile. This path must target the downloaded extracted driver.
You are ready to go.
Running the crawler
Running pipenv shell will enable your virtual environment. From there, you can run one crawl with the following command:
$ ./docsearch run /path/to/your/config.json
Or from the Docker image:
$ ./docsearch docker:run /path/to/your/config.json
This will start the crawl. It extracts content from parsed pages and push the built records to Algolia.
Create a new configuration
To create a configuration, run ./docsearch bootstrap. A prompt will ask you for some information and will create a JSON configuration you can use as a base.
$ ./docsearch bootstrap
# Enter your documentation url
start url: http://www.example.com/docs/
# Pick another name, or press enter
index_name is example [enter to confirm]: <Enter>
=================
{
"index_name": "example",
"start_urls": [
"http://www.example.com/docs/"
],
"stop_urls": [],
"selectors": {
"lvl0": "FIXME h1",
"lvl1": "FIXME h2",
"lvl2": "FIXME h3",
"lvl3": "FIXME h4",
"lvl4": "FIXME h5",
"lvl5": "FIXME h6",
"text": "FIXME p, FIXME li"
}
}
=================
Create a file from this text into a filename example.json, we'll use it later on to start the crawl. You can browse the list of live configurations.
Testing your results
You can test your results by running ./docsearch playground. This will open a web page with a search input. You can do live tests against the indexed results.
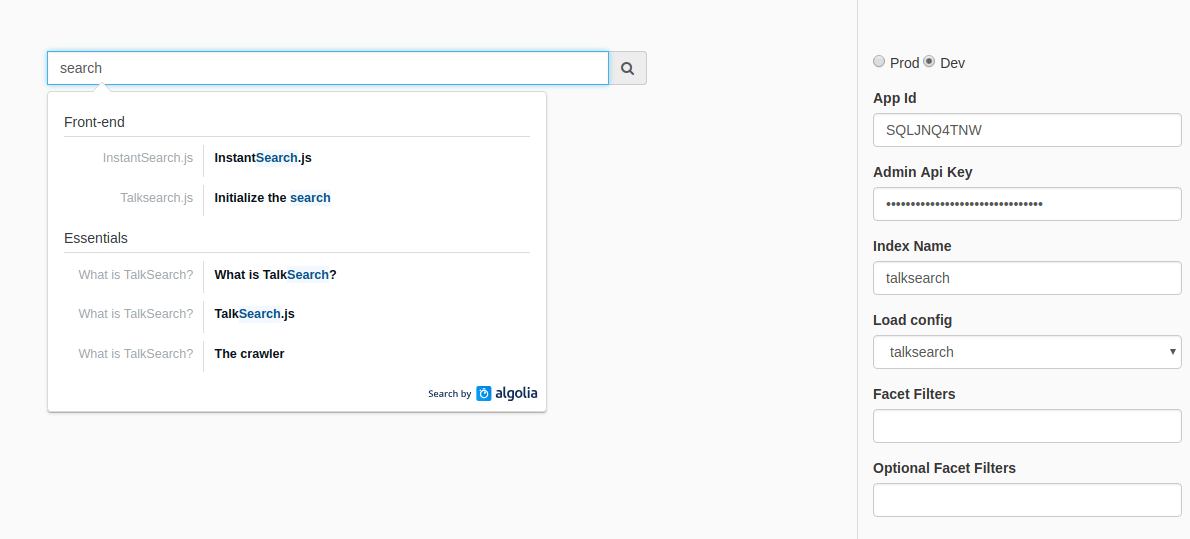
Note that if the command fails (it can happen on non-Mac machines), you can get the same result by running a live server in the ./playground subdirectory.`
Integration
Once you're satisfied with your config, you can integrate the dropdown menu in your website by following the instructions here.
The difference is that you'll also have to add the appId key to your docsearch() instance. Also don't forget to use a search API key here (in other words, not the write API key you used for the crawl).
docsearch({
appId: '<APP_ID>', // Add your own Application ID
apiKey: '<API_KEY>', // Set it to your own *search* API key
[…] // Other parameters are the same
});
Help
You can run ./docsearch without any argument to see the list of all available commands.
Note that we use this command-line tool internally at Algolia to run the free hosted version, so you might not need all the listed commands.